





近年,網絡雲端管理發展起來,各大網絡品牌都有自家的雲端管理系統,加速了雲使用的步伐。但現在大部分品牌都只有特定系列產品才能夠支援雲端管理,有的品牌雲端管理就功能並不齊全,又或者 License 的年費太高,中小企業難以負擔。巿場上還有什麼品牌可以給用家選擇呢?以下介紹的 Ruijie Cloud 網絡雲端管理系統,是少數向中小企巿場支援全企業級功能的網絡雲端系統。
 ▲ Ruijie Wi-Fi
▲ Ruijie Wi-Fi
企業級品牌 知名網絡供應商
網絡品牌供應商 Ruijie 為商用企業提供網絡解決方案,除商用巿場外,政府 Wi-Fi.HK 和眾多的 NGO 也有選用 Ruijie 產品,全港亦有超過 400 間中小學正採用 Ruijie 網絡方案。上年度 Ruijie 便推出了針對中小企業巿場的牌子 — Reyee,產品質量維持高水平兼附設適合中小企使用的企業級功能。
獨家自組網 3 分鐘自動配置設定完成
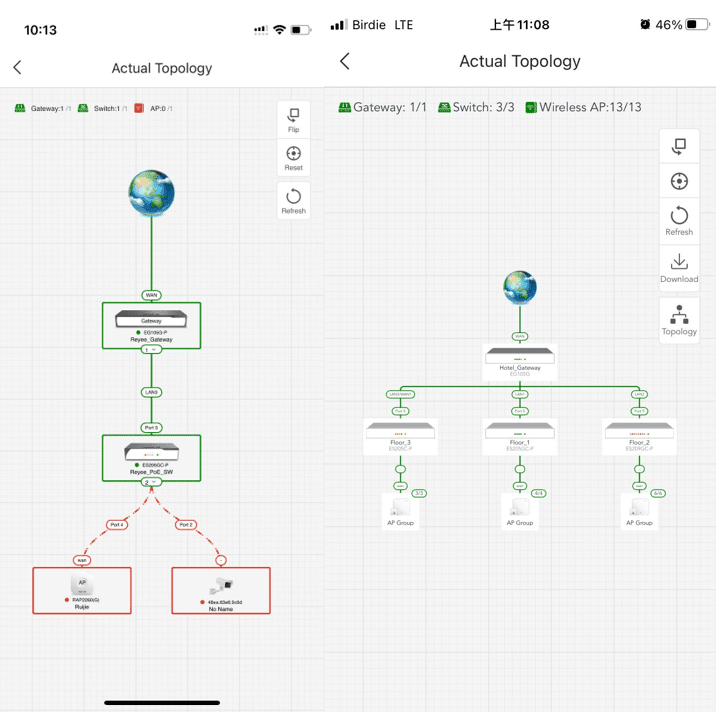
組裝 Ruijie 產品不會有太大難度,原因是 Ruijie 產品有個獨特功能名叫「自組網 SON : Self-Organizing Network」,只要使用全 Reyee 產品,3 分鐘內可以全部產品自動添加上 Ruijie Cloud,包括 Router、Switch、Gateway 和 Access Point。往後的功能設置亦都會自動套上設備上,大幅減少設置時間和所需要的技術門檻。如果設備裡有支援 ONVIF 的 CCTV Camera ,Ruijie Cloud 會自動 discover 並添加上雲端。
以下參考影片展示了 Ruijie 曾經試過不用 3 分鐘就能使用自組網功能去設置全部 150 台 AP
https://www.youtube.com/watch?v=TPCqAD8DR_k
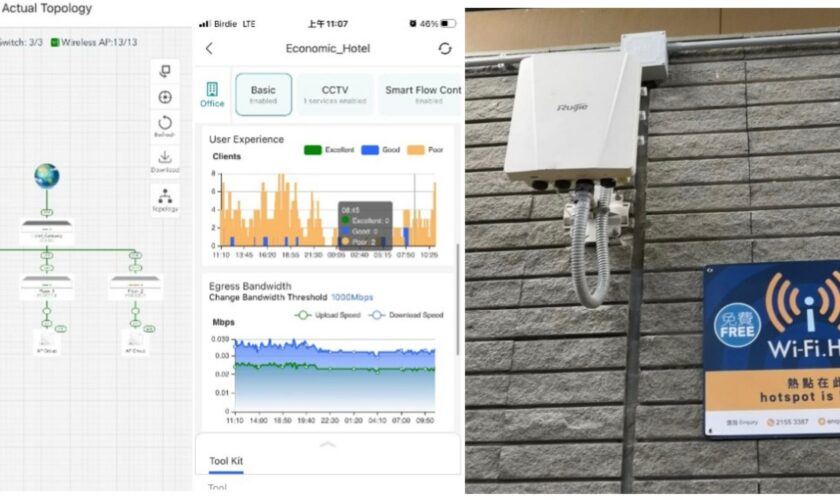
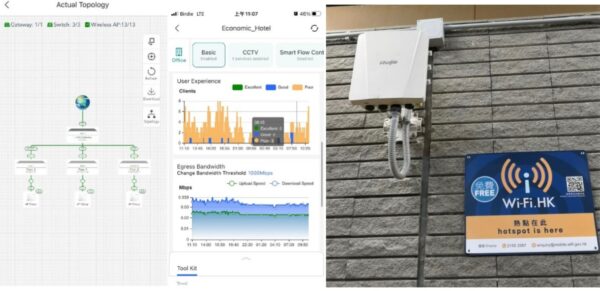
▲Ruijie Cloud 自動 discover Reyee 和 Camera,紅色連結代表有問題
手機網絡管理 遙遠設置
企業級的管理系統,由於功能複雜和定位原因,多數需要用獨立軟件或 Web GUI 登入系統去操作,就算有手機 App 也只會提供整體資訊為主 。Ruijie Cloud 給用家驚喜的地方是它的手機 App,除了必有的整體資訊如網絡狀態、設備的使用資料和用家使用量外,更加貼心地提供設備的內裡資訊,比如每一個網埠的連結應用和使用狀況,使管理者可以更快地偵查到每台設備的實際情形。
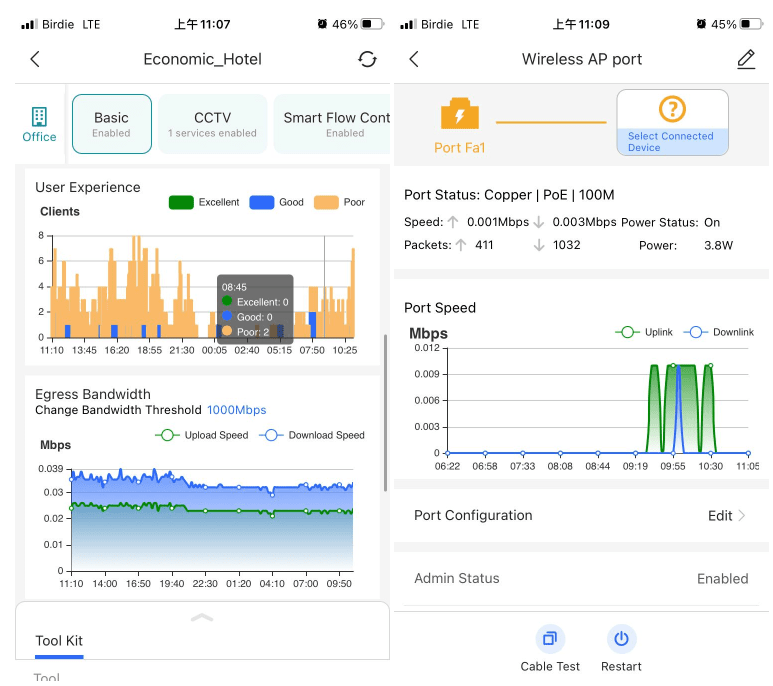
▲ Ruijie Cloud 提供豐富網絡資訊
系統的 alarm system 可以設計不同門檻和組合,當有異常時,就透過 EMAIL 和 App pop up 主動去通知管理者,再進入 App 裡查看設備狀況。App 裡已經有常用的 Wi-Fi 設置,網絡限制等設定,管理者可以於手機 App 內作出即時調整,十分方便。如果項目需要其他技術人員協助管理,亦設有 Share Tenant 功能,可以提供到 Read/Write 和 Read only 的選擇,共同管理項目。
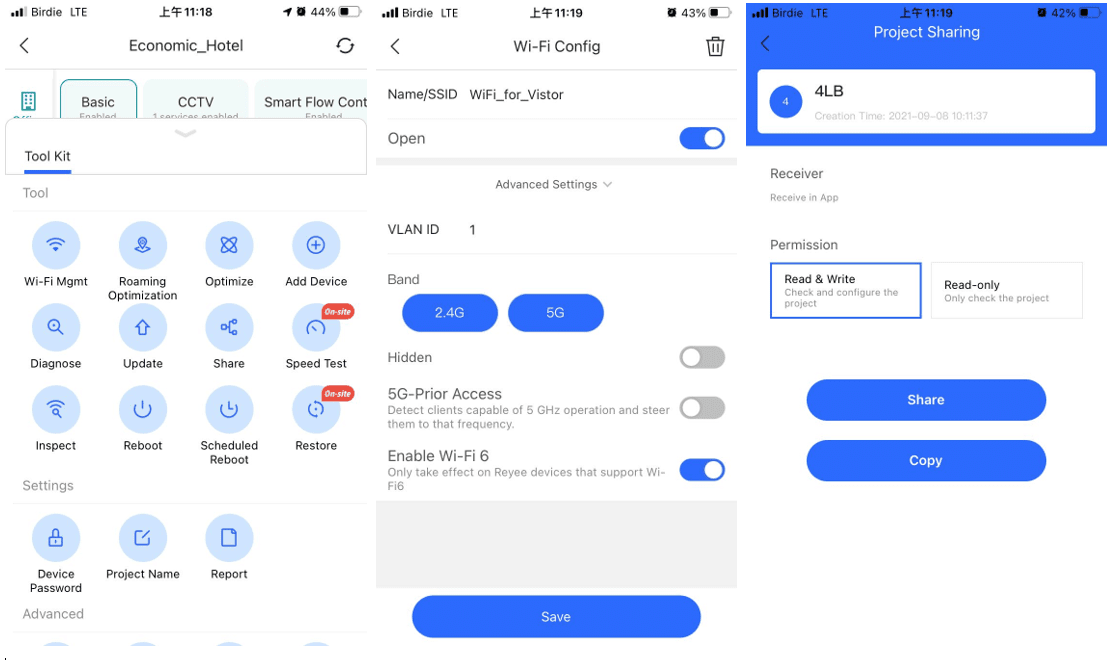
▲ 全面企業級功能
企業功能 節省運維成本
上面已介紹過 Ruijie Cloud 有提供企業級功能讓中小企使用,另外他們有幾個貼地功能,相信不少中小止都有這需求 :
Remote PoE Reboot : 當終端設備如 Wi-Fi 或者 CCTV Camera 有不穩定時,一般的做法是派遣工程司到現場做 onsite inspection,但這樣做的成本十分高昂,而且 8 成的不穩定問題都只需要重啓設備就可以。若果使用 Ruijie Cloud,當管理者知道終端設備有異常時,可以先透過 Cloud 去重啓該設備的網絡電接阜,如果問題解決就可以省郤派遣工程司到現場處理,這樣就更有效率,減省運維成本。
Long Distance : 眾所周知一般 PoE LAN 的傳輸距離限制是 100 米,如果要連接超過 100 米,就需要添加 PoE 交換機,增加運維成本。Ruijie Cloud 有一個 Long Distance 功能,可以把連接阜的傳輸速度限制於 10MB 內,換來達到 200 米的傳輸距離。對於一些有特別距離需求的 CCTV 項目,這功能就會大派用場。
AI Optimization / Diagnose : 網絡不穩定或者異常,有可能是設置問題,也有可能是外在因素影響,但一般情況下,如果没有相關專業知識者或者現場做詳細測試的話,是很難檢測到問題所在。Ruijie Cloud 有一個 AI Optimization 功能,可以一鍵幫助改善設備的配置,比如用大數據分析選擇最暢通的網絡頻普,調較合適的訊號強弱等等。另一個功能是 AI Diagnose,它可以協助你分析從手機直至 Internet 間的連接是否有硬體或者設置異常,並且提供解決建議,尤如一名專業網絡工程師從旁協助。
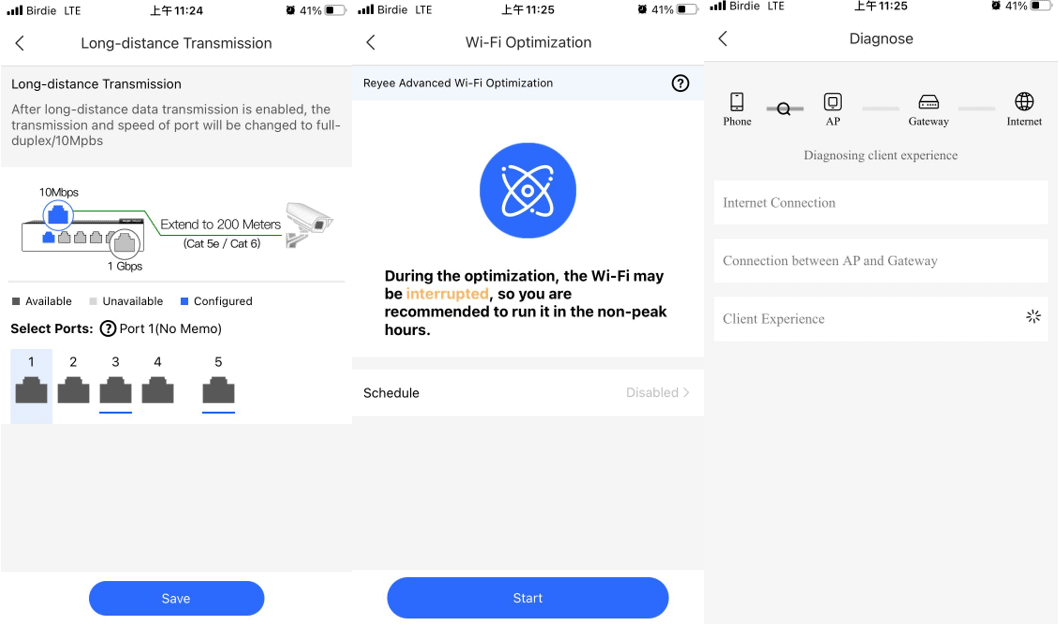
▲ 一鍵偵查和改善系統配置
Ruiji Cloud license 終身免費
很多品牌的雲端管理是需要額外收取 License Fee,每年以 Subscription 型式或者按產品型號和數量去收取費用。而 Ruijie cloud 則向所有客戶提供終身免費設備無上限,和企業級功能的網絡雲端管理系統,這策略十分關顧只用上有限設備的中小企業,幫助他們大大減輕運維成本。
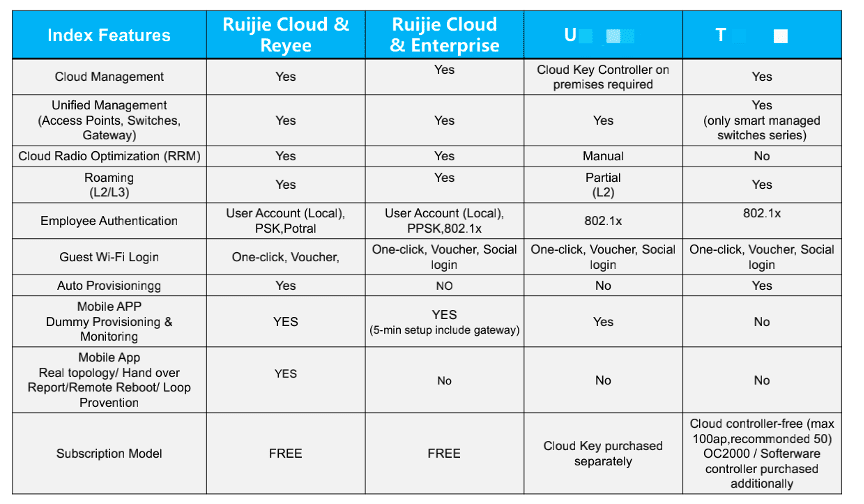
▲ Ruijie Cloud 比巿場對手牌子的雲端有更強大的功能且免費
Google 雲端系統 保證安全性
雲端管理的無間斷服務能力和資料安全一向是大眾關注焦點。香港區所使用的 Ruijie Cloud 是設置於 Singapore Google 內, 已通過 99.99 的認證,另外於俄羅斯亦有設置高可用性解決方案,雲端系統的穩定性有所保證。對於某些行業如酒店和銀行有著高度嚴格的私人條例規範,Ruijie Cloud 亦已經通過歐盟對私隱保障的嚴格需求 (GDPR),客戶不用擔心資料外洩。
總結
有賴於 Ruijie Cloud 的友善介面,產品設置和測試過程都可非常順利,相信網絡新手都能夠輕易掌握。而 Ruijie Cloud 是完全免費和無上限使用,所以中小企業若使用 Ruijie Reyee 產品的話,只需付上硬件費用就能用 Ruijie Cloud,整個配套相當吸引。
測試產品:
RG-EG210G-E
- 10 個 Gigabit Port,uplink 1000Mbps
- 最大支援 200 台設備同時使用
- 預設 2 WAN,最大支援 4 WAN
- 預設三個網段
- 支援網絡流量控制,行為管理
- 支援 IPSec VPN,DDNS
 ▲ RG-EG210G-E 全能中小企 Router
▲ RG-EG210G-E 全能中小企 Router
RG-ES209GC-P
- 8 個 Gigabit PoE/PoE+ Port,1 個 Gigabit Uplink Port
- 120W 最大 PoE 輸出功率
- 支援 Ruijie cloud
- 4K MAC 容量
- 支援 Loop Prevention、Remote PoE Reboot、Long Distance 功能

▲ RG-ES209GC-P 高性能交換機
RG-RAP2260(G)
- 2 個 Gigabit LAN Port
- AX1800 Wi-Fi 6 ,2×2 MIMO
- 4G : 574Mbps / 5G : 1201Mbps,共提供 1.775Gbps
- 內置藍牙 0
- 支援 Layer 2,3 Roaming

▲ RG-RAP2260(G) 全能中小企 Gateway































