
語言模型是科技企業爭相開發的技術之一,最近 Microsoft 與 Nvidia 就宣佈合作訓練了至今最強戴的解碼語言模型,比現有最大型的 GPT-3 的參數要多 3 倍。
Microsoft 和 Nvidia 表示,這個名爲 MT-NLG 的單體 Transformer 語言模型中共擁有 5,300 億個參數,使用以 NvidiaDGX SuperPOD 為基礎的 Selene 超級電腦以混合精度訓練完成。他們解釋,訓練所需的運算極為龐大,這超級電腦擁有幾千個 GPU 進行平行運算,再結合 Megatron-LM 和 PyTorch 深度學習最佳化函式庫 DeepSpeed 提升效率,才可以在合理的時間內訓練出這個規模的模型。
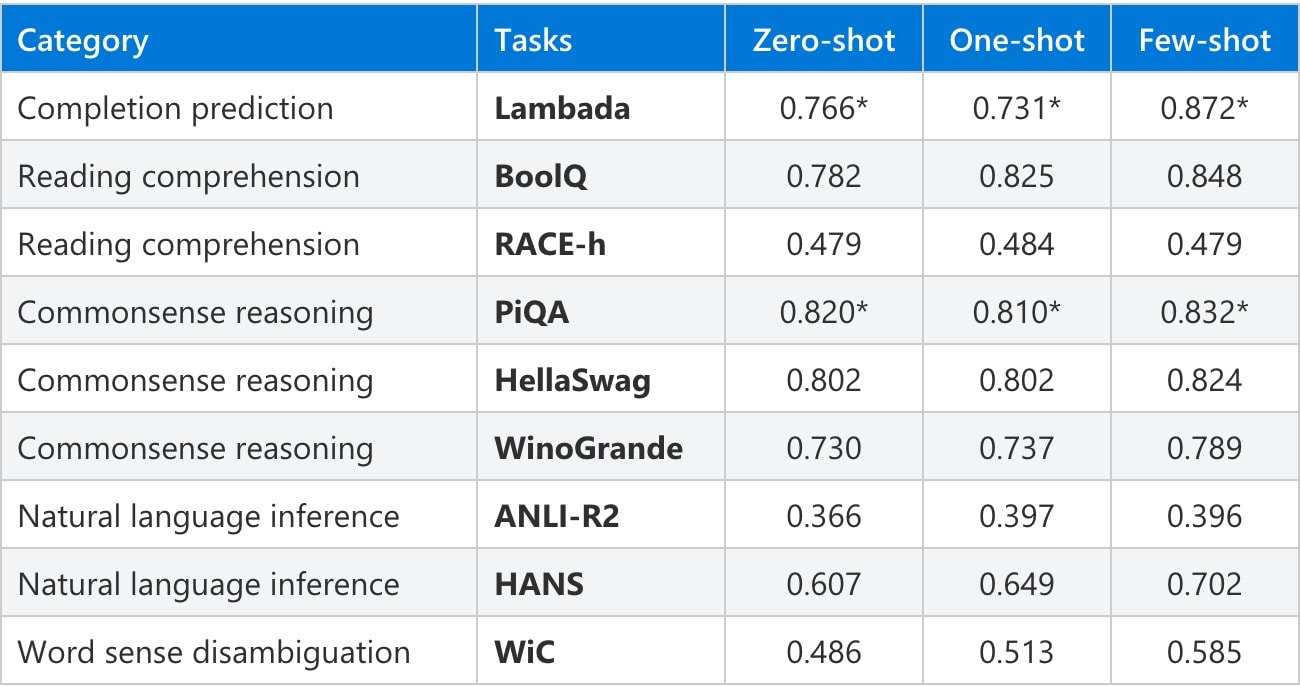
由於 MT-NLG 擁有極多參數,在不同的自然語言任務上都有相當優秀的表現,而且除了自然語言之外,它也可以進行幾本的數學運算,不只使用記憶算數,未來的發展潛能令人期待。Microsoft Turing 團隊主管 Ali Alvi 和 Nvidia 產品管理及營銷高級主管 Paresh Kharya 表示,他們期待著 MT-NLG 會如何塑造未來的產品,並鼓勵開發者社群進一步探索自然語言處理(NLP)的極限。
來源:Venture Beat
—
新增 : unwire.pro Mewe 專頁 : https://mewe.com/p/unwirepro




