
Facebook 在 4 號晚上出現服務故障,連同旗下各種服務包括 Instagram 和 WhatsApp 都無法使用,6 小時後才陸續恢復正常,事件引起極大不便,而專家就估計成因為 BGP 出錯。
Facebook 旗下系統大型故障正值歐美的辦公時間,因此雖然在亞洲並未造成太大影響,卻在歐美引起不少麻煩。Facebook 方面雖然就事件道歉,卻未有詳細解釋問題成因。而 Cloudflare 方面就對問題進行分析,認為今次的問題源於 DNS 伺服器設定錯誤,不過對於 Facebook 這樣大型的網絡服務而言單純的 DNS 錯誤不太可能發生。
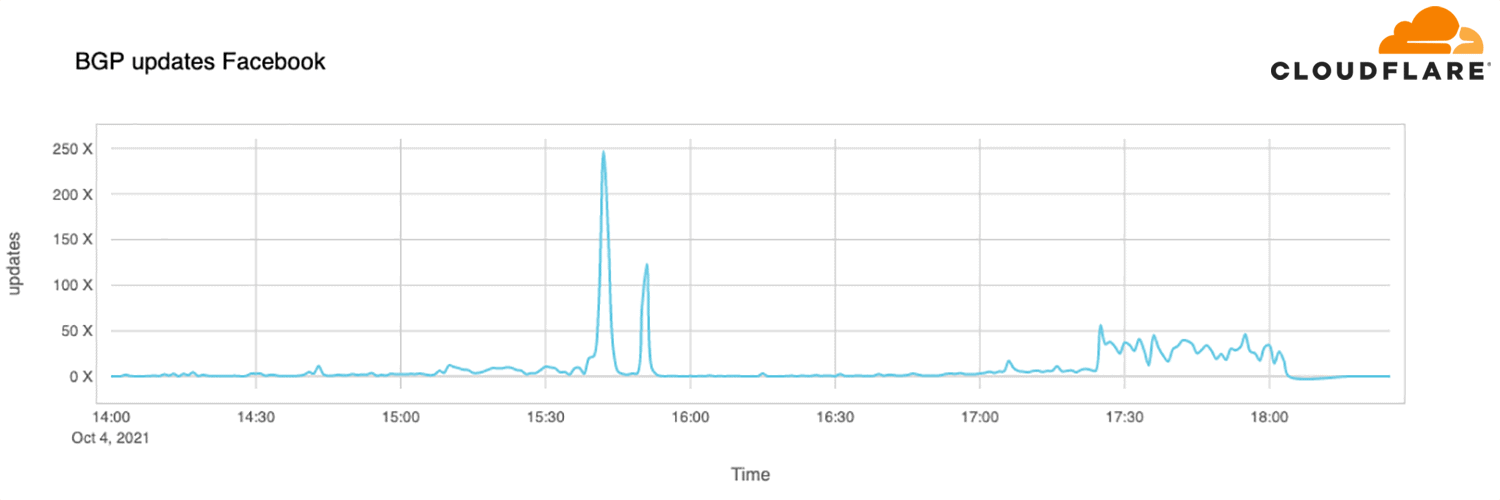
進一步分析之後,很有可能是由於 BGP(邊界閘道器協定)出現錯誤。Cloudflare 發現,在事件發生前,Facebook 忽然發出和撤回好幾次 BGP 資訊,令其他系統無法定位 Facebook DNS 伺服器的實體 IP 位置,同時造成全球無法正常連接 Facebook 服務。而由於 Facebook 故障,令更多人嘗試連接,造成類似 DDoS 的突發流量,影響到一些 Facebook 以外的服務。
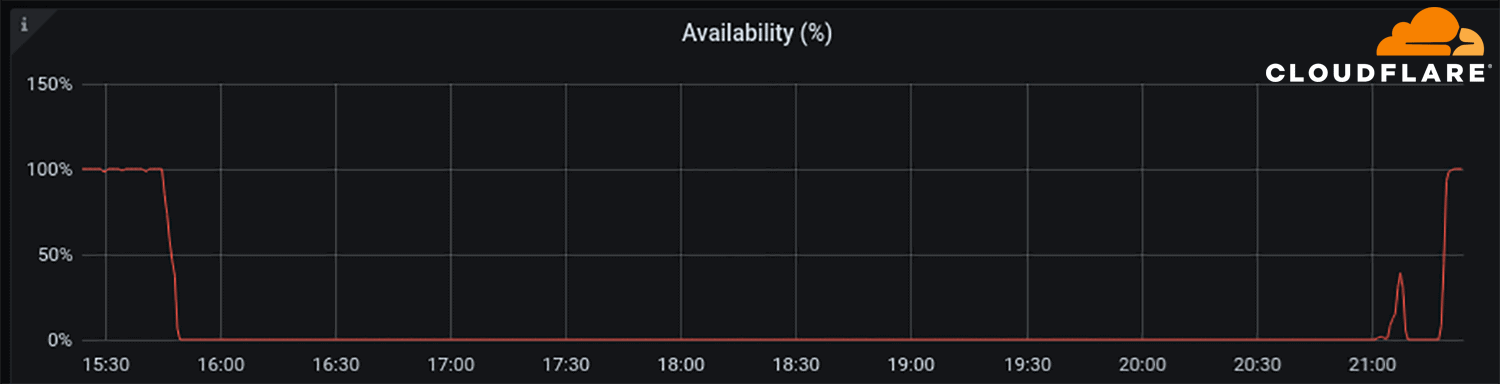
當然,最重要的是 Facebook 為什麼會在最初出現異常的 BGP 動作,仍然不得而知,可能是升級或更改 BGP 時錯誤造成。而故障的時間點剛好是 Facebook 被爆出醜聞之後,更令人懷疑這事件可能不是純粹的意外。
來源:Cloudflare
—
新增 : unwire.pro Mewe 專頁 : https://mewe.com/p/unwirepro



