一年一度的香港書展剛剛閉幕,這次且讓我們聊聊書本。
稍微看過書的大概都會見過國際書號 ISBN,一般印在封底那個條碼。但 ISBN 為甚麼需要存在,大概不是每個人都想過。不妨先考考自己:一疊有封面、有名字、釘裝好,滿載圍繞特定主題文字的紙,沒有 ISBN 的話,算是一本書嗎?
ISBN 與 metadata
是,但也不是。視乎語境。
當書泛指文字、圖片、概念的載體,那可以說是,比如動漫愛好者的同人誌一般都不會有 ISBN。但在出版社、印刷廠、書店、圖書館、貿易發展局等等,即體制的眼中,那只是一疊紙,不是書。圖書館不會上架,發行商不會推廣,書店很可能不會進貨或者根本不知道它的存在;甚至,在某些威權國家,書店出售「一疊紙」很可能違法——別怪我口吻不太確定,那可是因為威權國家的法律詮釋完全隨意。換言之,威權政府透過 ISBN 的批核,就能輕鬆牢牢審查學校、圖書館、書店、報攤等地方流通的內容。
當然,ISBN 有其積極、正面的意義,而且在很多民主國家,以及曾經享有高度出版自由的香港,申請 ISBN 都是近乎沒有門檻的。試想像,要不是 1967 年啟用的國際書號,我們根本沒法得知整個世界的書目。ISBN 是書本的 metadata(元資料),讓全人類得以搜尋、發現書目,讓知識有效傳達,作品相互引用。
metadata 可以理解為「data about data」:書是 data,ISBN 是 metadata;電影是 data,IMDb 上的各項周邊資料是 metadata;可見元資料對資料整理和發現的重要性。
對於 metadata 有個常見的誤解:只要有 data 就能抓出 metadata。實際上,能從 data 抽取的 metadata,一般只佔少數,很多進階的 metadata 需要額外花工夫整理,從 IMDb 就可看出,即使 Google 和最先進的 AI 都沒法從電影裡面抽取出那些包括票房、製作經費、花絮、時代背景等各種 metadata。
數位內容與 ISCN
來到網絡世界,整理知識、發現內容的角色很大程度由 Google 擔當,表面上我們好像不需要 metadata,有關鍵字就好,實際上,關鍵字正正就是 metadata 的一種。而想要內容在搜索結果名列前茅,單單讓 Google 分析網頁內容抽取關鍵字還不夠,還需要主動整理和提交更細緻的 metadata,具體體現為 JSON-LD 格式的 structured data(如嫌火星文,請忽略這句)。
〈RTHK 影片備份:無需硬盤,但要共識〉和〈dAppledaily 永久儲存蘋果日報,永遠幾遠?〉介紹的 IPFS 和 Arweave,目標是永續儲存 data;至於負責永續儲存 metadata 的,則是借用 ISBN 概念而設計的 ISCN,International Standard Content Number。
當然,不是任何內容都值得永續儲存,事實上,不值得的佔了大多數,比如即時通訊,我全都會設成自焚,以求數位環保。但對於少部分珍貴內容如一本用心寫成的書、一篇深刻的文章、一張經典的照片、一幅雋永的插畫,都值得永遠流傳,避免因為平台倒閉、費用過期、人為錯誤、政治審查等各種原因流失。
要做到這一點,採用的工具除了 IPFS 和 Arweave,也該加上 ISCN,否則假如不被搜尋、發現、引用、交互,data 即使永續存放也沒太大意義。
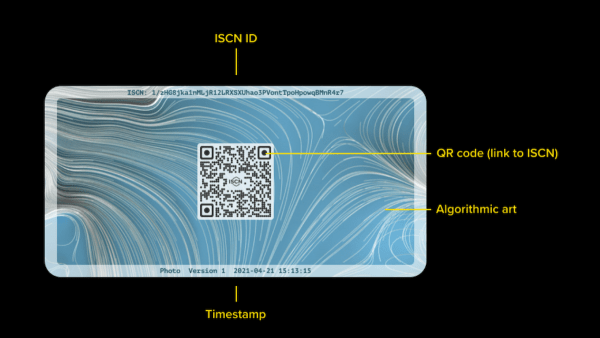
ISCN 就像是區塊鏈年代的 ISBN,但從物理世界搬到網絡,從只應用於書本改為應用到小至一篇文章、一張照片、一首歌曲,大至一部小說、一段影片甚至一齣電影的任何數位內容,從由各個國家政府負責當地號段的批核,變成不設任何「入閘機制」,所有人付出小量 LikeCoin 就可生成的「permissionless」機制。這種無需核准的模式,是無大台機制的核心原則,放諸金融,帶來的是 DeFi;放諸內容,帶來的將是 DePub,無大台出版。
無大台出版賦予了個體出版自由,那虛假訊息、內容農場等諸多問題該如何處理?請留意往後我們對 DAO,decentralized autonomous organization 的討論。