「圖片左邊是一隻貓,右邊是一隻狗。」如果你只是稍微瞥過,很可能會產生這樣的誤解,但只要看久一些,自然而然便會察覺其中的突兀之處:左右兩邊其實是相同的圖片,只是稍微修改過。

確實,為了讓人們被圖片混淆,研究人員修改了一些細節.之所以這麼做,是因為 Google 團隊正在設法弄清楚為什麼人類會對某些形式的圖像處理產生牴觸,或者更該這麼說:用一張圖片去欺騙人們到底需要什麼。
透過理解這些簡單攻擊與意外的原理,團隊希望讓人工智能(AI)變得比現在更聰明,或說,更具備與人類相同的常識去辨識圖片。
「如果我們確切地搞懂人類大腦中存在可以抵制某種對抗性類型的例子,這將為機器學習有類似的安全機制提供證據。」
過去一年在國外許多團隊的嘗試下,我們經常看到 AI「出錯」,不論是海龜誤認成步槍,還是將迷幻貼紙誤認為多士機,這些錯誤在身為人類的我們看來都非常有趣,因為這是即使四、五歲的小孩都不會犯的錯誤。
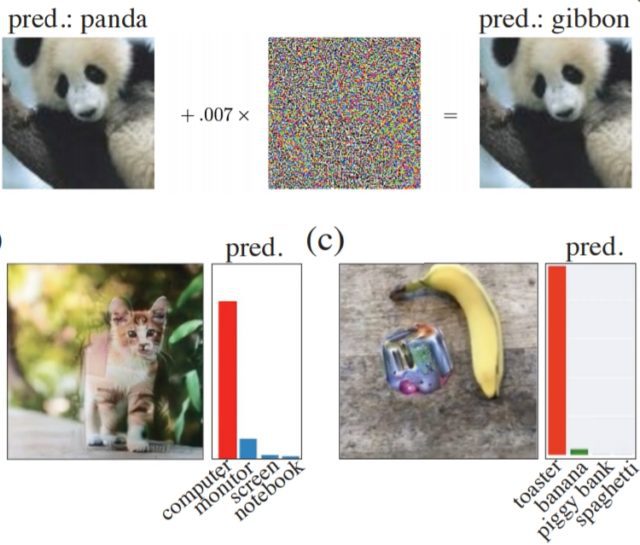
▲ 在有意圖的些微改動照片後,AI 便會將熊貓看成長臂猿、貓咪看成電腦、香蕉看成多士機。
而這些錯誤並不在於 Google 的 AI 系統有什麼問題,而是一個機器普遍存在的簡單缺陷:缺乏眼睛。由於機器無法「看到」世界,只能「處理」圖片,這讓人們很容易操縱一般人不會看到的圖片來欺騙它們。
而這也是為什麼 Google 要同時研究人類大腦和神經網路的原因。
截至目前為止,神經科學(neuroscience)已經提供 AI 領域許多幫助,像是對 AI 應用發展非常重要的人工神經網路(ANN)便是其中一環,但研究人員希望能從中獲取更多靈感,目標其實非常簡單:那些騙不了人類的內容也應該騙不了 AI。
身為 Google 研究小組成員之一,Ian Goodfellow 過去曾發表過深度學習相關書籍,他近日再度公布了一份白皮書──「能同時欺騙人類與電腦視覺的對抗式案例」(Adversarial Examples that Fool both Human and Computer Vision),提及一些欺騙 AI 的案例並不適用人類大腦,Goodfellow 認為這些資訊應該能用來製造更彈性的神經網路。
以目前的情況來看,人類在圖像辨識還是毫無疑問的冠軍,而 AI 的錯誤確實能當作茶餘飯後的話題,但如果人們未來得生活在 AI 環繞的世界(目前看來確實正持續朝這個目標邁進),為了避免 AI「看錯」照片造成的麻煩──像是自駕車被迷幻貼紙搞混標示造成的車禍,這些問題勢必得解決。
(本文由 TechNews 授權轉載)




