日前於烏鎮舉辦的圍棋人機大戰,中國頂尖棋士柯潔失利,以四分一子負於 AlphaGo。面對加強版的 AlphaGo,在賽前外界普遍不看好柯潔能獲勝。昨日的人工智能論壇上,AlphaGo 團隊負責人就揭露了更多 AlphaGo 的開發細節,指 AlphaGo 化身 Master 在經過網上 60 場頂尖水平的對弈和自我學習後,棋力早已比去年對決李世石時更進一步 ,而且使用了最新的硬件和機器學習技術。面對更強的 Master 版本,柯潔僅負半目於首戰落敗,已表現出作為世界頂尖棋士的實力。
{kind=link}
去年三月,由 DeepMind 研發團隊開發的 AlphaGo 一鳴驚人,在五局的對弈中以四勝一負的成績壓倒性擊敗南韓職業九段棋士李世石。事隔一年,Google 於中國烏鎮舉辦為期 5 天的圍棋暨人工智能高峰會,掀起人工智能與人類頂尖棋士的第二次正式公開對決:DeepMind 的圍棋人工智能 AlphaGo 與世界排名第一的柯潔九段展開三番棋對弈。而在 23 日的首局對弈中,執白棋的 AlphaGo 以四分之一子的優勢先拔頭籌獲勝。柯潔亦在賽後表示,AlphaGo 實在出色,這一局輸得心服口服,還形容 AlphaGo 已接近圍棋之神了。
AlphaGo 快速自我完善 進步神速全靠獨特演算法
AlphaGo 能屢屢擊敗人類頂尖棋手,在於其先進的機器學習演算法。一直以來,圍棋被認為是傳統遊戲中對人工智能最具挑戰的項目。不單是因為圍棋包含了龐大的搜索空間,更是因為對於落子位置的評估難度已遠遠超過了簡單的啟發式演算法,以現時的電腦運算能力,亦無法就所有可能的棋局情況作窮舉搜索。DeepMind 的研究科學家 David Silver 就在首日賽后的人工智能峰會上詳細解構了 AlphaGo 背後演算法的細節。
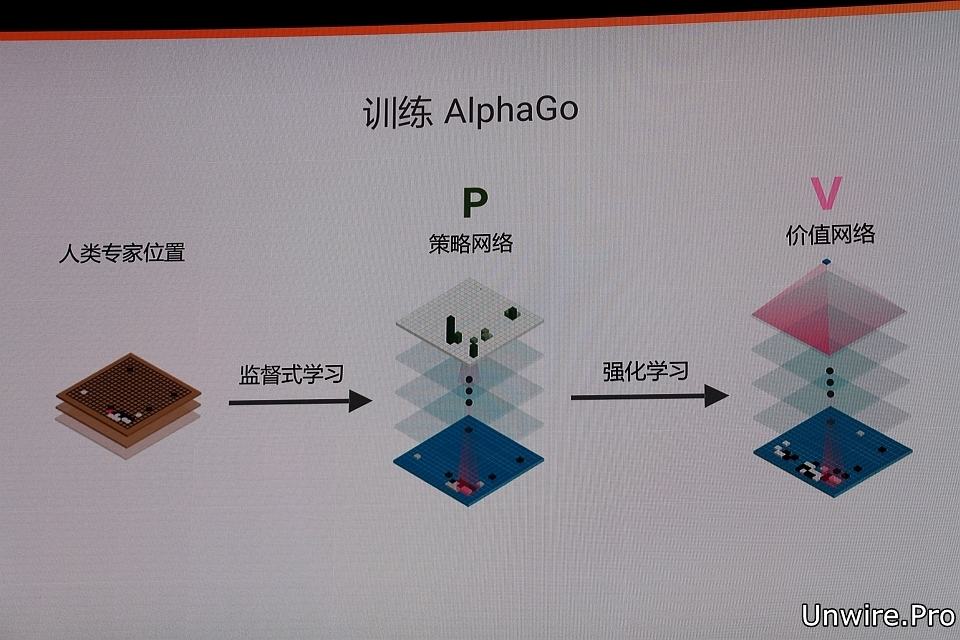
為了應對圍棋的複雜性,在訓練 AlphaGo 時,團隊採用了新穎的機器學習技術,結合了人類專家監督學習和強化學習的優勢。通過訓練形成策略網絡 (Policy network),以棋盤上的局勢作為輸入資訊,並對所有可行的落子位置產生一個概率分佈,然後訓練出價值網絡 (Value network) 對自我對弈進行預測,以對手的絕對勝利到 AlphaGo 的絕對勝利為標準,預測所有可行落子位置的結果。
{kind=link}
在獲取棋局資訊後,AlphaGo 就會根據策略網絡探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。在分配的搜索時間結束時,類比過程中被系統最頻繁考察的位置將成為 AlphaGo 的最終選擇。
{kind=link}
{kind=link}
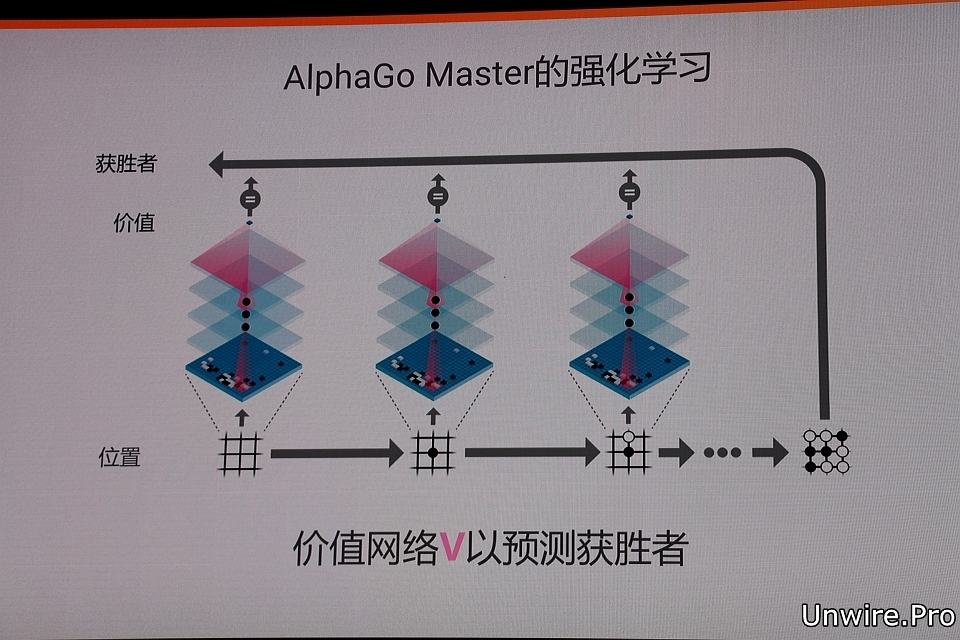
David Silver 解釋,AlphaGo 透過將這兩種網絡整合進基於概率的蒙特卡羅樹搜索 (MCTS) 中,實現了它真正的優勢。而去年在網上突然出現,與世界頂級圍棋選手進行了 60 場網上對局並取得全勝戰績的 Master,正是 AlphaGo 的升級版本。
{kind=link}
對比李世石時期的 AlphaGo,其主要通過預判 50 個回合和預測對手可能落子的位置來限制減少搜索樹規模,新的 Master 版本已經可以考慮到整個棋局最有價值的位置,而且能以最少的回合預測數來達到更高的準確度。現時最新版本的 AlphaGo 更能產生大量自我對弈棋局,為下一代版本提供了訓練資料,此過程循環往復,能不斷將 AlphaGo 達致近乎完美。
{kind=link}
DeepMind 創辦人:AlphaGo 已具備有限創造力
{kind=link}
David Silver 亦提到,AlphaGo 經過前期的全盤探索和過程中對最佳落子的不斷揣摩後,其搜索演算法已可在計算能力之上加入近似人類的直覺判斷。DeepMind 的聯合創始人兼 CEO Demis Hassabis 更表示,雖然領域有限,但 AlphaGo 已明顯展現出具備通過組合現有知識產生新穎或獨特想法的能力,即人類所說的創造力。
除了演算法上的改進,硬件上的提升亦功不可沒。David Silver 透露,AlphaGo Lee 版本時,需要在 Google Cloud 上 50 個 TPU (Tensor Processing Unit) 運作,而搜索 50 個棋步為每秒 10,000 個位置。他解釋,每秒 10,000 個位置看似很多,但 20 年前由 IBM 研發,應用於分析國際象棋的深藍 (Deep Blue),它已可每秒搜索 1 億個位置。相較之下,AlphaGo 透過策略網絡和價值網絡進行判斷無疑更聰明,亦大幅節省無意義的窮舉搜索分支。
而現時的 AlphaGo Master 版本,已可在單個 TPU 機(包含 4 個 TPU)上運作,亦能透過產生大量自我對弈進行自我學習,進一步調整出更強大的策略及價值網絡,縮減搜索樹的分支和規模。他又指,目前運作 AlphaGo 的 TPU 是上週 Goolge I/O 大會上公佈的最新版本,專為機器學習而設計,對比舊版,新版本在處理計算時所消耗的電量僅為以往的十分之一,運作效率亦提升了 10 倍。
AlphaGo 與柯潔的對決固然吸引,人工智能的討論亦是今次峰會的另一重點議題。適逢 Google 上週在其 I/O 2017 會上提出將「流動為先」轉為「AI 為先」的策略,DeepMind 及 AlphaGo 團隊的代表在烏鎮現場的演講中不時提到 AlphaGo 只是 AI 在不同領域和行業應用的開始。想了解包括 Alphabet 董事長 Eric Schmidt 在內等多名業界領袖和專家對 AI 未來的見解,請繼續留意 Unwire.Pro 接下來的報導。